DISTRIBUCIÓN EN EL MUESTREO
Muestreo
Es un procedimiento por medio del cual se estudia una
parte de la población llamada muestra, con el objetivo de inferir con respecto
a toda la población. Es importante relacionar el muestreo con lo que es el
censo, el cual se define como la enumeración completa de todos los elementos de
la población de interés.
1.- Teoría del
Muestreo
Uno de los propósitos de la estadística inferencial es
estimar las características poblacionales desconocidas, examinando la
información obtenida de una muestra, de una población. El punto de interés es
la muestra, la cual debe ser representativa de la población objeto de estudio.
Se seguirán ciertos procedimientos de selección para asegurar de que las
muestras reflejen observaciones a la población de la que proceden, ya que solo
se pueden hacer observaciones probabilísticas sobre una población cuando se
usan muestras representativas de la misma. Una población está formada por la
totalidad de las observaciones en las cuales se tiene cierto observa. Una
muestra es un subconjunto de observaciones seleccionadas de una población.
Muestras Aleatorias
Cuando nos interesa estudiar las características de poblaciones grandes, se utilizan muestras por muchas razones; una enumeración completa de la población, llamada censo, puede ser económicamente imposible, o no se cuenta con el tiempo suficiente.
Cuando nos interesa estudiar las características de poblaciones grandes, se utilizan muestras por muchas razones; una enumeración completa de la población, llamada censo, puede ser económicamente imposible, o no se cuenta con el tiempo suficiente.
A continuación se
verá algunos usos del muestreo en diversos campos:
- Política. Las muestras de las opiniones de los votantes se usan para que los candidatos midan la opinión pública y el apoyo en las elecciones.
- Educación. Las muestras de las calificaciones de los exámenes de estudiantes se usan para determinar la eficiencia de una técnica o programa de enseñanza.
- Industria. Muestras de los productos de una línea de ensamble sirve para controlar la calidad.
- Medicina. Muestras de medidas de azúcar en la sangre de pacientes diabéticos prueban la eficacia de una técnica o de un fármaco nuevo.
- Agricultura. Las muestras del maíz cosechado en una parcela proyectan en la producción los efectos de un fertilizante nuevo.
- Gobierno. Una muestra de opiniones de los votantes se usaría para determinar los criterios del público sobre cuestiones relacionadas con el bienestar y la seguridad nacional.
2.- Distribución Muestral de Media Aritmética
En matemáticas y estadística, la media aritmética
(también llamada promedio o simplemente media) de un conjunto finito de números
es el valor característico de una serie de datos cuantitativos objeto de
estudio que parte del principio de la esperanza matemática o valor esperado, se
obtiene a partir de la suma de todos sus valores dividida entre el número de
sumandos. Cuando el conjunto es una muestra aleatoria recibe el nombre de media
muestral siendo uno de los principales estadísticos muestrales.
Las muestras aleatorias obtenidas de una población
son, por naturaleza propia, impredecibles. No se esperaría que dos muestras
aleatorias del mismo tamaño y tomadas de la misma población tenga la misma
media muestral o que sean completamente parecidas; puede esperarse que
cualquier estadístico, como la media muestral, calculado a partir de las medias
en una muestra aleatoria, cambie su valor de una muestra a otra, por ello, se
quiere estudiar la distribución de todos los valores posibles de un
estadístico. Tales distribuciones serán muy importantes en el estudio de la
estadística inferencial, porque las inferencias sobre las poblaciones se harán
usando estadísticas muestrales. Como el análisis de las distribuciones
asociadas con los estadísticos muestrales, podremos juzgar la confiabilidad de
un estadístico muestral como un instrumento para hacer inferencias sobre un
parámetro poblacional desconocido.
Como los valores de un estadístico, tal como x, varían
de una muestra aleatoria a otra, se le puede considerar como una variable
aleatoria con su correspondiente distribución de frecuencias. La distribución
de frecuencia de un estadístico muestral se denomina distribución muestral. En
general, la distribución muestral de un estadístico es la de todos sus valores
posibles calculados a partir de muestras del mismo tamaño.
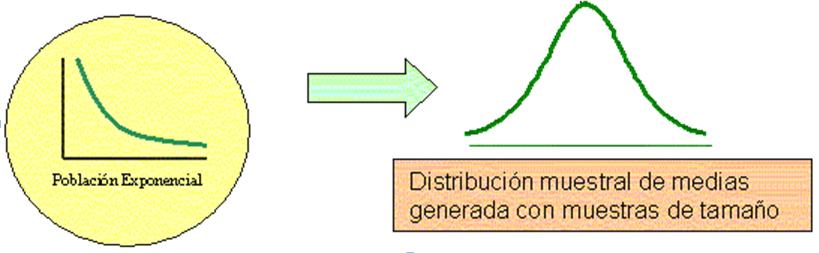
Suponga
que se han seleccionado muestras aleatorias de tamaño 20 en una población
grande. Se calcula la media muestral x para cada muestra; la colección de todas
estas medias muestrales recibe el nombre de distribución muestral de medias, lo
que se puede ilustrar en la siguiente figura:

Suponga que se eligen
muestras aleatorias de tamaño 20, de una población grande, y se calcula la
desviación estándar de cada una. La colección de todas estas desviaciones
estándar muestrales se llama distribución muestral de la desviación estándar, y
lo podemos ver en la siguiente figura:

Ejemplo 1
Se eligen muestras ordenadas de tamaño
2, con reemplazo, de la población de valores 0, 2, 4 y 6. Encuentre:
 la media poblacional.
la media poblacional. la desviación
estándar poblacional.
la desviación
estándar poblacional.
la media de la
distribución muestral de medias.

la desviación estándar de la
distribución muestral de medias.
Además, grafique las frecuencias para
la población y para la distribución muestral de medias.
Solución:
a. La
media poblacional es:

b. La desviación estándar de la población es:

c. A continuación se listan los elementos de la
distribución muestral de la media y la correspondiente distribución de frecuencias.

La Media de
la Distribución Muestral de Medias es:
d. La Desviación Estándar de la Distribución Muestral de
Medias es:

De aquí que podamos deducir que:

Como para cualquier
variable aleatoria, la distribución muestral de medias tiene una media o valor
esperado, una varianza y una desviación estándar, se puede demostrar que la
distribución muestral de medias tiene una media igual a la media poblacional.
Esto es:
Distribuciones
Muestrales
Después de haber realizado el
ejercicio anterior se puede ver que una distribución muestral se genera
extrayendo todas las posibles muestras del mismo tamaño de la población y
calculándoles a éstas su estadístico. Si la población de la que se extraen las
muestras es normal, la distribución muestral de medias será normal sin importar
el tamaño de la muestra.

Si la población de donde se extraen
las muestras no es normal, entonces el tamaño de la muestra debe ser mayor o
igual a 30, para que la distribución muestral tenga una forma acampanada.
Mientras mayor sea el tamaño de la muestra, más cerca estará la distribución
muestral de ser normal.
Para muchos propósitos, la
aproximación normal se considera buena si se cumple n=30. La forma de la
distribución muestral de medias sea aproximadamente normal, aún en casos donde
la población original es bimodal, es realmente notable.
Los símbolos usados para representar
los estadísticos y los parámetros, en éste y los siguientes capítulos, son
resumidos en la tabla siguiente:
Tabla 1
Símbolos para estadísticos y parámetros
correspondientes.

3.- Distribución
en el muestreo: Para dos Muestras
Cuando el tamaño de la
muestra (n) es más pequeño que el tamaño de la población (N), dos o más
muestras pueden ser extraídas de la misma población. Un cierto estadístico puede ser calculado
para cada una de las muestras posibles extraídas de la población. Una
distribución del estadístico obtenida de las muestras es llamada la
distribución en el muestreo del estadístico. Por ejemplo, si la muestra es de
tamaño 2 y la población de tamaño 3 (elementos A, B, C), es posible extraer 3
muestras (AB, BC Y AC) de la población.
Podemos calcular la media para cada muestra. Por lo tanto, tenemos 3 medias muéstrales
para las 3 muestras. Las 3 medias
muéstrales forman una distribución. La
distribución de las medias es llamada la distribución de las medias muéstrales,
o la distribución en el muestreo de la media.
De la misma manera, la distribución de las proporciones (o porcentajes)
obtenida de todas las muestras posibles del mismo tamaño, extraídas de una
población, es llamada la distribución en el muestreo de la proporción.
4.- DISTRIBUCIÓN CHI2
CUADRADO DE PEARSON
Si (X1,X2,...,Xn)
son n variables aleatorias normales independientes de media 0 y varianza 1, la
variable definida como:

Se dice que tiene una
distribución CHI con n grados de libertad. Su función de densidad es:

Siendo
la función gamma de
Euler, con P>0. La función de distribución viene dada por

La media de esta
distribución es E(X)=n y su varianza V(X)=2n. Esta distribución es básica en un
determinado número de pruebas no paramétricas.
Si consideramos una
variable aleatoria Z~N (0,1), la variable aleatoria X=Z2 se
distribuye según una ley de probabilidad distribución CHI con un grado de
libertad
Si tenemos n variable
aleatoria independientes Zi~N (0,1), la suma de sus cuadrados
respectivos es una distribución CHI con n grados de libertad

La media y varianza de esta
variable son respectivamente, E(X)=n y V(X)=2n
Ejemplo,
El espesor
de un semiconductor se controla mediante la variación estándar no mayor a
=0.60 mm. Para mantener controlado el proceso se toman muestras aleatoriamente
de tamaño de 20 unidades, y se considera que el sistema está fuera de control
cuando la probabilidad de que 2 tome valor mayor o igual al valor de la
muestra observado es que es 0.01. Que se puede concluir si s=0.84mm?

con n=20 y =0.60,
excede
Entonces,

Por tanto, el sistema está
fuera de control
La función de distribución CHI tienen
importantes variaciones de acuerdo con los grados de libertad y del tamaño
muestral (menor tamaño muestral y mayor tamaño muestral respectivamente)

En consecuencia, si tenemos
X1,..,Xn, variable aleatoria independientes, donde cada

La distribución Chi muestra
su importancia cuando queremos determinar la variabilidad (sin signo) de
cantidades que se distribuyen en torno a un valor central siguiendo un
mecanismo normal.
Teorema
(Cochran).
Sean X1,…,Xn con distribución N(,), la variable
aleatoria independiente, entonces

La función Chi-cuadrado es
igual a la función normal elevada al cuadrado. Esto es, el producto de dos
distribuciones de Gauss es una distribución de Chi-cuadrado. Si de una
población normal, o aproximadamente normal, se extraen muestras aleatorias e
independientes, y se le calcula el estadígrafo χ2 usando el valor
muestral de la varianza y el poblacional con:

Esta función matemática
está caracterizada por el valor del número de grados de libertad υ=n-1 (donde n
es el tamaño muestral). Al igual que la t-Student, el valor total del área bajo
la curva es igual a la unidad, pero la diferencia principal es que esta no es
simétrica respecto al origen, sino que se extiende desde 0 hasta + ∞ porque no
puede ser negativa.

A medida que los grados de
libertad aumentan, la curva cambia de forma y sus valores se han tabulado en el
anexo de tablas estadísticas, donde se muestran los valores del área bajo la
curva, para los principales valores de χ2, a la derecha de éste. O
sea, se muestra la zona de rechazo para diferentes niveles de significación y
de grados de libertad, lo cuales varían entre 1 y 100. Más allá, conviene usar
directamente la función de Gauss.
Relación con otras distribuciones. La Chi cuadrado es una
distribución binomial inversa cuyo coeficiente de variabilidad es 10.1, esta tiene
un intervalo de confianza de 2.3 grados en la escala de desviaciones estándar.
Posee una distribución de Poisson elevada la cual asciende a 56.5 m Eq en los tres
primeros cuartiles de la recta. Para k=2 la distribución es una distribución exponencial.
La prueba de Chi-cuadrado es una prueba no paramétrica que mide la discrepancia entre una distribución observada y otra teórica (bondad de ajuste), indicando en qué medida las diferencias existentes entre ambas, de haberlas, se deben al azar. También se utiliza para probar la independencia de dos muestras entre sí, mediante la presentación de los datos en tablas de contingencia. La fórmula que da el estadístico es la siguiente:

Los grados de libertad nos
vienen dados por: gl= (r-1)(k-1). Donde r es el número de filas y k
el de columnas.

En caso contrario se
rechaza. Donde representa el valor proporcionado por las tablas, según
el nivel de significación elegido. Cuanto más se aproxima a cero el valor de
Chi-cuadrado, más ajustadas están ambas distribuciones.
DISTRIBUCION JI-CUADRADA (X2)
En realidad la distribución
ji-cuadrada es la distribución muestral de s2. O sea que si se
extraen todas las muestras posibles de una población normal y a cada muestra se
le calcula su varianza, se obtendrá la distribución muestral de varianzas. Para estimar la varianza poblacional o la
desviación estándar, se necesita conocer el estadístico X2. Si se
elige una muestra de tamaño n de una población normal con
varianza

el
estadístico:

Tiene una
distribución muestral que es una distribución ji-cuadrada con
gl=n-1 grados de libertad y se denota X2 (X es
la minúscula de la letra griega ji). El estadístico ji-cuadrada está dado por:

Donde n es
el tamaño de la muestra, s2 la varianza muestral y
la varianza de la población de donde se extrajo la muestra. El estadístico ji-cuadrada también se puede dar con la siguiente expresión:
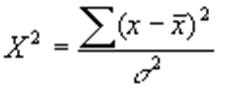
Propiedades de
las distribuciones ji-cuadrada
- Los valores de X2 son
mayores o iguales que 0.
- La forma de una distribución X2 depende
del gl=n-1. En consecuencia, hay un número infinito de distribuciones X2.
- El área bajo una curva
ji-cuadrada y sobre el eje horizontal es 1.
- Las distribuciones X2 no
son simétricas. Tienen colas estrechas que se extienden a la derecha; esto
es, están sesgadas a la derecha.
- Cuando n>2, la media de una
distribución X2 es n-1 y la varianza es 2(n-1).
- El valor modal de una distribución X2 se da en el valor (n-3)
La siguiente
figura ilustra tres distribuciones X2. Note que el valor modal
aparece en el valor (n-3) = (gl-2).

La función de
densidad de la distribución X2 esta dada por:

La
tabla que se utilizará para estos apuntes es la del libro de probabilidad y estadística
de Walpole, la cual da valores críticos

(gl)
para veinte valores especiales de

Para
denotar el valor crítico de una distribución X2 con gl grados
de libertad se usa el símbolo
(gl);
este valor crítico determina a su derecha un área de
bajo
la curva X2 y sobre el eje horizontal. Por ejemplo para
encontrar X20.05(6) en la tabla se localiza 6 gl en el
lado izquierdo y  a o largo del
lado superior de la misma tabla.
a o largo del
lado superior de la misma tabla.
DISTRIBUCIÓN
t-STUDENT
Si (X,X1,X2,...,Xn)
son n+1 variables aleatorias normales independientes de media 0 y varianza 2,
la variable

Tiene una distribución
t-Student con n grados de libertad. Su función de densidad es

Siendo

La función gamma de Euler
con P>0. La media de la distribución t-Student es E(X)=0 y su varianza
V(X)=n/(n-2), la cual no existe para grados de libertad menores que 2.
Esta distribución aparece
en algunos contrastes del análisis normal.
La distribución t-Student se construye como un
cociente entre una normal Z~N(0,1) y la raíz de una Chi X2n independientes. De modo preciso,
llamamos distribución t-Student con n grados de libertad, tn a la de
una variable aleatoria T,

Para calcular

Sea un estadígrafo t
calculado para la media con la relación

Ejemplo, En 16 recorridos de
prueba de una hora cada uno, el consumo de gasolina de un motor es de 16.4 gal , con una desviación
estándar de 2.1 gal .
Demuestre que la afirmación que el consumo promedio de gasolina de este motor es 12.0 gal/hora
Solución, Sustituyendo
n=16, =12.0,  =16.4 y s=2.1 en la fórmula de t-Student, se tiene
=16.4 y s=2.1 en la fórmula de t-Student, se tiene

Para el cual en las tablas,
para =5% y 15 gl es insignificante, y por tanto se puede concluir que el
consumo de 12 gal/h es real
Ejemplo, Encuentre los valores de
la función para:
a.
14 gl, =97.5%→t0.975=-t2.5%=-2.145
b.
P(-t0.025<T<t0.05)=0.925
DISTRIBUCIÓN
F SNEDECOR O F-FISHER
Si U y V son dos variables
aleatorias independientes que tienen distribución Chi Cuadrada con n1
y n2 grados de libertad, respectivamente, entonces, la variable
aleatoria

Que es la llamada función
de distribución F-Snedecor o F-Fisher con n1 y n2 grados
de libertad. Ejemplo, Un valor de f
con 6 y 10 grados de libertad para un área de 0.95 a la derecha es,
f0.95,6,10=1/(f0.05,10,6)=1/4.06=0.246
Si de dos poblaciones normales, o aproximadamente
normales, se extraen dos muestras aleatorias e independientes, y a cada una se
le calcula su respectiva varianza, el cociente de ambos valores

(con F>1, esto es,
siempre se coloca el más grande como numerador) tendrá una distribución de
Fisher, cuyos valores críticos fueron obtenidos por W. Snedecor en una tabla
que se caracteriza por tener dos grados de libertad: el correspondiente al
numerador υ1=n1-1 y el del denominador υ2=n2-1.
Programas de computación permiten calcular los valores críticos respectivos.

En las Tablas se presenta
una hoja para cada nivel de confianza, se eligen los más apropiados como: 95%;
97,5%; 99%; 99,5% y 99,9%. Como siempre, el área total bajo la curva es la
unidad y se extiende desde 0 a
+ ∞. La forma es muy parecida a la Chi-cuadrado. Se muestran tres casos, con diferentes
grados de libertad, y se marca el valor de
F=2,5 con una, línea punteada vertical.
El principal uso de esta
función es el Análisis de Varianza, que se verá más adelante, y es para cuando
se necesita comparar más de dos medias muéstrales a la vez. En estos casos la
idea es detectar si el efecto de uno o más tratamientos afecta a las muestras
testeadas. En cambio, cuando se tiene el caso de dos muestras, la idea es
testear si hay homocedasticidad en las dos poblaciones en estudio. Una vez
verificado este supuesto, se puede avanzar más verificando si hay diferencia
entre las medias muéstrales, y así verificar si ambas muestras tienen igual
media y varianza, porque eso significa que en realidad provienen de la misma
población normal. Eso probaría que no hay efecto de un tratamiento si se lo
compara con un placebo, o que dos técnicas de laboratorio son equivalentes.
Si el experimento no
verifica esto, entonces se deberá elegir el caso que presente menor varianza,
para tener menor variabilidad en las mediciones. En Genética se puede verificar
si una generación de crías es más variable en un carácter que la de sus padres.
En Sistemática se puede testear si dos poblaciones locales tienen la misma
variabilidad. En Bioquímica y Farmacia el uso más frecuente es comparar el
error casual de mediciones de laboratorio, al introducir algún efecto o cambiar
el método de medición. En el caso de testear si dos técnicas de laboratorio
tienen igual dispersión, o bien, para elegir aquella con mayor precisión, conviene
pensar el problema como la incidencia de un factor en estudio en lugar de dos
técnicas totalmente diferentes entre sí. Por ejemplo, se trata de una misma
práctica, pero se usan dos espectrofotómetros diferentes, y se trata de
determinar si la modificación de la varianza se debe al uso de un aparato
diferente. El factor acá sería: tipo de espectros.
También se puede estudiar
la incidencia del factor humano, realizando las mismas mediciones a dos
personas diferentes. De esa forma se puede imaginar que las dos muestras
provienen de diferentes poblaciones, o que el efecto del factor analizado no es
despreciable cuando se rechaza la hipótesis nula. En la figura se muestra el
caso de dos poblaciones. En el caso (a) ambas poblaciones tienen la misma
media, pero por efecto del error casual sus varianzas son diferentes. Si esta
diferencia es significativa, resulta evidenciada por el Modelo de Fisher que
permite la comparación de ambas.

En el caso (b) hay un error
sistemático que desplaza la media, pero sus varianzas permanecen iguales. Es lo
mismo que sumar una constante a todos los valores; ocurre un desplazamiento
hacia la derecha. t-Student se usa para detectar esto cuando se hace el test de
comparación de dos medias independientes. Como se verá más adelante, se puede
construir todo un bagaje de métodos para efectuar un Control de Calidad interno
en un laboratorio de medición clínica. Por ahora, basta decir que se puede
controlar la exactitud con los modelos de t-Student y la precisión con los de
Chi-cuadrado y Fisher.
Con esto se pueden comenzar
a controlar y calibrar los sistemas de medición. Las limitaciones de todo esto
son dos: la primera es que se puede estudiar el efecto del factor analizado en
solo dos muestras y no en más de dos. La segunda es que si la calidad se
entiende como exactitud y precisión, solo se pueden emplear estos modelos para
magnitudes de tipo cuantitativas como las de la Química Clínica ,
pero no en magnitudes cualitativas como las usuales en Microbiología,
Bacteriología, Micología, etc. En magnitudes cuantitativas, por calidad se
entiende precisión y exactitud, en lugar de la capacidad de una prueba clínica
para diagnosticar. Sin embargo, a pesar de estas limitaciones sigue siendo una
herramienta sencilla y poderosa de control.
Para poder aplicar este modelo se deben tener en
cuenta los requisitos siguientes:
- Las muestras fueron extraídas de una población normal o aproximadamente normal.
- La selección de las muestras se hizo en forma aleatoria.
- Las muestras son independientes entre sí.
Que buena información, muy completa; Gracias...
ResponderEliminarGracias a Dios hemos terminado este trabajo!! :D
ResponderEliminarQue gran trabajo de Estadística hemos realizado...
ResponderEliminarQue buena información, muy completa; Gracias a Dios...
ResponderEliminarAl fin, con muchos tropiezos hemos terminado...
ResponderEliminarComo sufrimos, pero al fin terminamos nuestro blog
ResponderEliminar